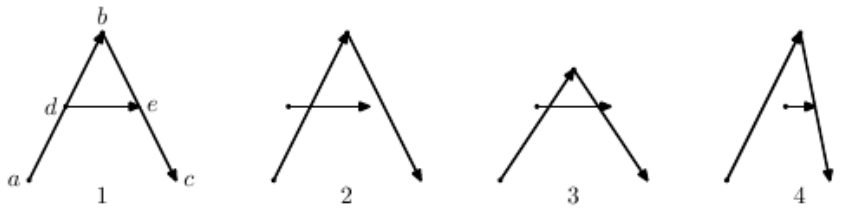3141 - 국어공잭에 글자쓰기 숙제
Time Limit: 3s
Memory Limit: 128MB
- Description
초등학교 때 국어공책에 똑같은 글자를 여러번 반복해서 쓰는 숙제를 해본 기억이 있을 것이다. 글씨의 모양과 쓰는 순서를 올바르게 익혀두기 위해서 이는 반드시 필요한 작업이다.
여기 글자쓰기 숙제를 채점하는데 회의감을 느낀 초등학교 선생 pichulia는 숙제검사를 자동으로 하는 프로그램을 만들기로 결심했다. 각 글씨를 2차원 평면상에 놓인 꼭지점들과, 꼭지점들 사이을 이은 선분들의 집합으로 본다면 '같은 글씨'는 다음과 같은 특징을 가진다고 한다.
- 두 글씨에 존재하는 선분과 꼭지점의 개수가 같아야한다.
- 두 글씨에 대응되는 각 꼭지점들의 위치관계가 똑같아야 한다. 위치관계는 꼭지점으로부터 8방향으로 정해진다. 예를 들어 글자 1에서 점 a1과 점 b1이 글자 2에서 점 a2와 점 b2와 대응된다고 치자. 글자 1에서 b1이 a1의 "오른쪽 위"에 위치해있다면, b2도 a2의 "오른쪽 위"에 위치해야한다. b1이 a1의 "정확히 왼쪽"에 위치해있다면 b2는 a2의 "정확히 왼쪽"에 위치해있어야 한다. 이는 꼭지점 사이에 선분이 존재하지 않더라도 만족해야하는 성질이다.
- 대응되는 선분에 대해, 두 글씨의 선분의 방향이 같아야 한다. 역시나 8방향이다.
- 대응되는 선분에 대해, 선분의 양 끝 꼭지점도 서로 대응되어야 한다.
어렵다. (원래 채점이란 엄청 고되고 힘든 작업이다. 시험보는 당사자들은 그걸 몰라요.
그러니까 조교를 위해 답안지를 최대한 백지로 제출하자.) 아래의 예시를 보자.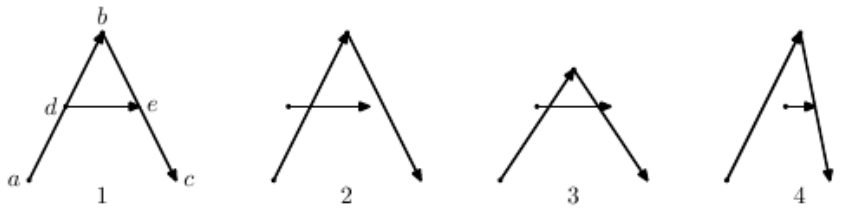
위 예시는 a->b->c 그리고 d->e 순서대로 선을 이어서 'A' 를 쓴 모습이다.
1이 원본 모습이고 2,3,4는 1과 같은 글씨로 판정되는 글씨들을 모아놓은 것이다.
아래의 예시는 이 1과 같은 글씨로 판정이 되지 못한 글씨들을 모아놓은 것이다.
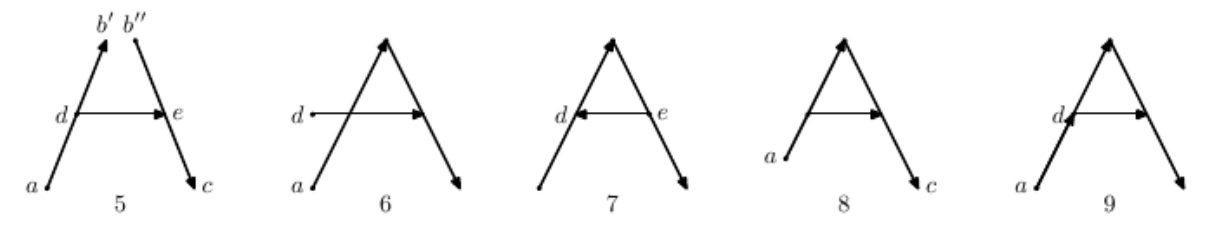
각 글씨들이 1과 다르게 된 이유는 다음과 같다.
5. b의 위치에 해당되는 꼭지점이 b'과 b'' 2개가 존재한다.
6. 점 a와 점 d의 위치관계가 잘못되었다. 원본 글씨는 점 d가 점 a의 "오른쪽 위"에 존재했으나, 6번 글씨의 경우 점 d가 점 a의 "정확히 위"에 존재한다.
7. 선분 d->e 의 방향이 반대이다.
8. 점 a와 점 c의 위치관계가 잘못되었다. 원본 글씨는 점 c가 점 a의 "정확히 오른쪽"에 존재했으나, 8번 글씨의 경우 점 c가 점 a의 "오른쪽 아래"에 존재한다.
9. 글씨 1에서 추가적으로 선분 a->d가 추가적으로 그려졌다.
아직 학년이 저학년이기 때문에 안타깝게도 글씨를 쓰는 순서까지는 고려하지 않고 채점하게 되었다. 주어진 글씨 2개의 선분정보가 주어졌을 때 두 글씨가 같은 글씨인지 다른 글씨인지 판별하시오.
- Input
입력으로 여러 테스트케이스들이 들어온다. 각 테스트케이스의 첫번째 줄에는 글자의 개수 n(2 ≤ n ≤ 20) 이 들어온다. 그 다음 n개에 걸쳐 글자정보들이 들어온다.
각 글자정보의 첫번째 줄에는 글자를 이루고있는 선분의 개수 m (1 ≤ m ≤ 100) 이 주어진다. 이어서 m개의 줄에 걸쳐 선분의 시작점과 끝점을 나타내는 4개의 정수 x1 y1 x2 y2 (-1000 ≤ x1, y1, x2, y2 ≤ 1000) 이 들어온다. 이는 (x1,y1) 에서 시작해서 (x2,y2) 에서 끝나는 선분을 의미하며, 두 점은 서로 다른 점이다.
- Output
각 테스트케이스마다 2~n번째 글씨가 1번째 글씨와 같은지를 알아내보자. 만약 i번째 글씨가 1번째 글씨와 같은 글씨라면 CORRECT를, 다른 글씨라면 INCORRECT를 테스트케이스의 i-1번째 줄에 출력한다.
각 테스트케이스 사이는 공백으로 된 줄로 구분되어야한다.
- Sample Input
-
9 3 0 0 10 20 10 20 20 0 5 10 15 10 3 0 0 10 20 10 20 20 0 2 10 13 10 3 0 0 10 15 10 15 20 0 5 10 15 10 3 8 10 12 10 0 0 10 20 10 20 14 0 3 0 0 8 20 12 20 20 0 5 10 15 10 3 0 0 10 20 10 20 20 0 0 10 15 10 3 0 0 10 20 10 20 20 0 15 10 5 10 3 2 4 10 20 10 20 20 0 5 10 15 10 4 0 0 10 20 0 0 5 10 10 20 20 0 5 10 15 10
- Sample Output
-
CORRECT CORRECT CORRECT INCORRECT INCORRECT INCORRECT INCORRECT INCORRECT
- Hint
2
1 1 2 2
2 2 3 3
과
1
1 1 3 3
은 서로 다른 글씨이다.
2
1 1 2 2
2 2 3 1
과
2
2 2 3 1
1 1 2 2
는 같은 글씨이다. (글씨를 쓰는 순서는 고려하지 않음)
- Source
Regionals 2007, Europe - Northeastern